2022. 5. 1. 21:01
CRM 분석을 진행할 때 RFM형 모델을 사용해 고객 가치분석을 하는 경우가 있다. 오늘은 전통적인 CRM 분석에서 자주 사용했던 RFM 모형에 대한 정의, 활용, 그리고 파이썬을 활용해 RFM 모형을 구축해보는 작업을 해보자.
RFM 모형의 정의
■ Recency (최근성) 고객이 최근에 구매했는가?
고객의 마지막 활동 시점이 언제인지를 나타내는 변수로 최근에 구매한 고객일수록 더 가치있게 평가된다.
여기서 활동은 꼭 구매뿐만 아니라, 비즈니스 목적에 따라 클릭, 방문 등으로 바꿀 수 있다.
■ Frequency (빈도) 고객이 얼마나 자주 방문했는가?
일정 기간 동안 고객이 얼마나 자주 특정 행동을 했는지를 의미하며 자주 할수록 가치 있는 고객으로 평가된다.
■ Monetary (구매금액) 고객이 얼마나 구매했는가?
일정 기간 동안 고객의 총 구매금액을 의미하며, 구매 금액이 높은 고객일수록 더 가치있게 평가된다.
마케팅 전략을 위한 고객 세분화
1. RFM 각 점수별 기준 설정
|
|
R
|
F
|
M
|
|
5점
|
1일~60일
|
13회~15회
|
2,805,001원~3,500,000원
|
|
4점
|
61일~120일
|
10회~12회
|
2,105,001원~2,805,001원
|
|
3점
|
121일~180일
|
7회~9회
|
1,405,001원~210,500원
|
|
2점
|
181일~240일
|
4회~6회
|
705,001원~140,500원
|
|
1점
|
241일~300일
|
1회~3회
|
5000원~705,001원
|
RFM 모델을 이용하여 고객 세분화를 진행하기 위한 RFM 각 변수에 대해 점수별 기준점을 선정한다.
2. 각 점수별 비율 산정
|
Recency기준
|
Frequency기준
|
Monetary기준
|
|||||||||
|
기준(일)
|
고객수(명)
|
고객율(%)
|
금액비율(%)
|
기준(일)
|
고객수(명)
|
고객율(%)
|
금액비율(%)
|
기준(일)
|
고객수(명)
|
고객율(%)
|
금액비율(%)
|
|
5점
|
***
|
38.0
|
83
|
5점
|
***
|
12.2
|
50.9
|
5점
|
***
|
5.8
|
45.3
|
|
4점
|
***
|
8.3
|
4.6
|
4점
|
***
|
15.7
|
18.7
|
4점
|
***
|
17.4
|
20.2
|
|
3점
|
***
|
12.4
|
7.1
|
3점
|
***
|
22.5
|
15.2
|
3점
|
***
|
22.9
|
18.7
|
|
2점
|
***
|
18.1
|
2.9
|
2점
|
***
|
28.3
|
13
|
2점
|
***
|
18.1
|
10.6
|
|
1점
|
***
|
23.2
|
1.5
|
1점
|
***
|
21.3
|
2.2
|
1점
|
***
|
35.8
|
5.2
|
|
계
|
***
|
100%
|
100%
|
계
|
***
|
100%
|
100%
|
계
|
***
|
100%
|
100%
|
고객 데이터 분석하여 각 점수별 고객 비율, 고객 매출액 비율등 필요 항목에 따라 값을 산정한다.
3. 고객 세분화 기반 매트릭스 분석
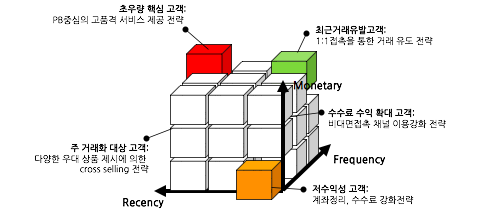
1차적으로 고객의 분포 변화를 파악한 다음에 매트릭스, 또는 입방체 형태를 이용하여 세밀한 고객 세분화 작업을 추가적으로 수행한다.
위의 예시를 통해 다음 아래와 같이 인사이트를 도출할 수 있다.
▶기준치가 모두 우수한 초우량 핵심 고객군 -> 이들에게 PB중심의 고객 품격 서비스 제공을 목표로 삼음
▶모두 낮은 고객 -> 계좌 정리, 수수료 강화 등으로 최소한의 비용으로 기본적인 수익 창출 및 타기업의 전환 유도
▶최근 성과 빈도가 우수하지만 수익은 낮은 고객 -> 인터넷 뱅킹과 같은 비대면 접촉채널로 전환
RFM 모형의 활용
1. 고객 세그먼트
세 가지 변수를 측정한 지표를 바탕으로 고객을 분류하고 차별화된 마케팅을 위한 고객 세분화로 활용될 수 있다.
다음 아래와 같은 예시로 고객 유형에 맞춰 마케팅 담당자는 그에 맞는 전략을 취하게 된다.
▶초우량 고객: R, F, M이 모두 높은 고객의 경우 → VVIP 프리미엄 서비스 제공하는 VIP 제도 운영
▶저수익성 고객: R(최근성), F(빈도)는 높지만, M(구매금액)이 낮은 고객으로 상품에 대한 관심이 많지만 구매가 망설이는 고객 → 마케팅 비용을 절감하는 디 마케팅 전략 수립
▶신규 고객: R(최근성), M(구매금액)은 높지만 F(빈도)가 낮은 고객 → 성장시키기 위한 우대 서비스 제시하고, CROSS- SELLING 전략 구사하여 핵심 우량 고객으로 양성
▶이탈 고객: F(빈도), M(구매금액)은 높지만 R(최근성)이 낮은 고객 → 재 활성화를 위한 프로모션, 할인 서비스 등을 제공하는 전략
2. 고객등급
고객을 평가하는 지수로 활용될 수 있으며, RFM지수를 바탕으로 고객 스코어링을 통해 고객에게 등급 부여할 수 있다.
파이썬 활용 RFM 고객가치분석
▷활용 데이터: Brazilian E-Commerce Public Dataset by Olist
>>import plotly
>>import pandas as pd
>>import numpy as np
>>import matplotlib.pyplot as plt
>>from matplotlib import style
>>import seaborn as sns
>>from datetime import datetime
#데이터 불러오기
>>customers_ = pd.read_csv("~/olist_customers_dataset.csv")
>>order_items_ = pd.read_csv("~/olist_order_items_dataset.csv")
>>order_payments_ = pd.read_csv("~/olist_order_payments_dataset.csv")
>>orders_ = pd.read_csv("~/olist_orders_dataset.csv")
>>df1 = order_payments_.merge(order_items_, on = 'order_id')
>>df2 = df1.merge(orders_, on = 'order_id')
>>df = df2.merge(customers_, on = 'customer_id')
#Recency 도출을 위한 데이터 추출
>>df_user = pd.DataFrame(df['customer_unique_id'])
>>df_user.columns = ['customer_unique_id']
>>df_max_purchase = df.groupby('customer_unique_id')['order_purchase_timestamp'].max().reset_index()
>>df_max_purchase.rename(columns = {'order_purchase_timestamp' : 'maxPurchaseDate'}, inplace = True)
#가장 최근 날짜에서 고객번호별 최근 구매날짜 차이 구하기
>>df_max_purchase['recency'] = (df_max_purchase['maxPurchaseDate'].max() - df_max_purchase['maxPurchaseDate']).dt.days
>>df_user = pd.merge(df_user, df_max_purchase[['customer_unique_id', 'recency']], on ='customer_unique_id')
>>df_user.recency.describe()
count 115018.000000
mean 237.228564
std 152.514177
min 0.000000
25% 113.000000
50% 218.000000
75% 345.000000
max 694.000000
Name: recency, dtype: float64고객 데이터를 가지고 와서 고객의 최근 구매 날짜를 보게 되면, 데이터 상 전체 고객의 가장 최근에 구매한 날짜를 기준으로 잡고 이 날짜와 고객 각 한 명당 최근에 구매한 날짜 차이를 구해 그 평균을 보게 되면 평균 237일 전인 것을 확인할 수 있다.
그 시간 차이의 흐름은 그래프를 통해 시각적으로 확인할 수 있다.
>>sns.set(palette='muted', color_codes=True, style='white')
>>fig, ax = plt.subplots(figsize=(12, 6))
>>sns.despine(left=True)
>>sns.distplot(df_user['recency'], bins=30)
>>plt.show()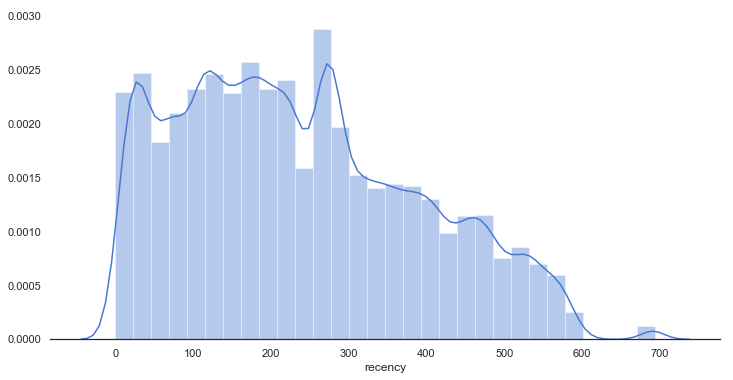
#kmeans 계산을 위한 elbow point 구하기
>>from sklearn.cluster import KMeans
>>point={}
>>df_recency = df_user[['recency']]
>>for k in range(1,10):
kmeans = KMeans(n_clusters=k, max_iter=100).fit(df_recency)
df_recency['cluster'] = kmeans.labels_
point[k] = kmeans.inertia_
>>plt.plot(list(point.keys()), list(point.values()))
>>plt.show()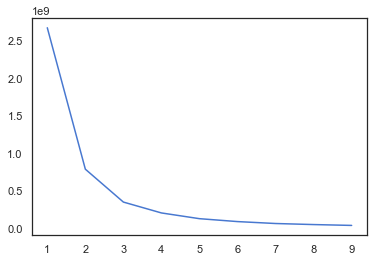
군집 수를 구하기 위해 elbow point를 이용하였고, 위의 그래프를 보고 elbow point은 대략적으로 5인 지점으로 설정했다.
>>kmeans = KMeans(n_clusters=5)
>>kmeans.fit(df_user[['recency']])
>>df_user['recencycluster'] = kmeans.predict(df_user[['recency']])
#cluster 분석 모형
>>def order_cluster(cluster_field_name, target_field_name,df,ascending):
df_new = df.groupby(cluster_field_name)[target_field_name].mean().reset_index()
df_new = df_new.sort_values(by=target_field_name,ascending=ascending).reset_index(drop=True)
df_new['index'] = df_new.index
df_final = pd.merge(df,df_new[[cluster_field_name,'index']], on=cluster_field_name)
df_final = df_final.drop([cluster_field_name],axis=1)
df_final = df_final.rename(columns={"index":cluster_field_name})
return df_final
>>df_user = order_cluster('recencycluster', 'recency',df_user,False)
>>df_user.groupby('recencycluster')['recency'].describe()
count mean std min 25% 50% 75% max
recencycluster
0 14071.0 511.273612 49.201608 446.0 471.0 505.0 542.0 694.0
1 18838.0 379.004034 35.095253 321.0 349.0 378.0 408.0 445.0
2 27357.0 261.409840 31.255823 208.0 232.0 266.0 283.0 320.0
3 30215.0 152.776634 31.176377 101.0 125.0 153.0 180.0 207.0
4 24537.0 48.262257 27.790502 0.0 24.0 44.0 73.0 100.0
군집의 그룹이 4로 갈수록 가장 최신성이 될 수 있도록 ascending False로 설정해 주었다.
그룹 0의 최신성 평균은 511일, 그룹 4의 최신성 평균은 48로 도출된 것을 확인할 수 있다.
#Frequency 도출을 위한 데이터 추출
>>df_frequency = df.groupby('customer_unique_id').order_purchase_timestamp.count().reset_index()
>>df_frequency.rename(columns = {'order_purchase_timestamp' : 'frequency'}, inplace = True)
>>df_user = pd.merge(df_user, df_frequency, on ='customer_unique_id')
>>df_user.frequency.describe()
# 분포 그래프
>>sns.set(palette='muted', color_codes=True, style='whitegrid')
>>fig, ax = plt.subplots(figsize=(12, 6))
>>sns.despine(left=True)
>>sns.distplot(df_user['frequency'], hist=False)
>>plt.show()
#kmeans 계산을 위한 elbow point 구하기
>>point={}
>>df_frequency = df_user[['frequency']]
>>for k in range(1, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(df_frequency)
df_frequency["clusters"] = kmeans.labels_
point[k] = kmeans.inertia_
>>plt.figure(figsize=(10, 5))
>>plt.plot(list(point.keys()), list(point.values()))
>>plt.xlabel("Number of cluster")
>>plt.show()
#kmeans
>>kmeans = KMeans(n_clusters=5)
>>kmeans.fit(df_user[['frequency']])
>>df_user['frequencycluster'] = kmeans.predict(df_user[['frequency']])
>>df_user = order_cluster('frequencycluster','frequency',df_user,True)
>>df_user.groupby('frequencycluster')['frequency'].describe()
count mean std min 25% 50% 75% max
frequencycluster
0 100150.0 1.207968 0.405856 1.0 1.0 1.0 1.0 2.0
1 12428.0 3.921307 1.048323 3.0 3.0 4.0 5.0 6.0
2 1968.0 9.850610 2.563686 7.0 7.0 9.0 12.0 16.0
3 397.0 24.536524 6.099081 18.0 20.0 22.0 24.0 38.0
4 75.0 75.000000 0.000000 75.0 75.0 75.0 75.0 75.0
빈도성 또한 군집의 그룹이 4로 갈수록 빈도가 높게 될 수 있도록 ascending으로 설정해 주었다.
군집 그룹 0은 구매 횟수의 평균이 1이었고 군집 그룹 4의 구매 횟수 평균은 75회인 것을 확인할 수 있었다.
#Monetary 도출을 위한 데이터 추출
>>df_revenue = df.groupby('customer_unique_id').payment_value.sum().reset_index()
>>df_user = pd.merge(df_user, df_revenue, on ='customer_unique_id')
# 분포 그래프
>>sns.set(palette='muted', color_codes=True, style='white')
>>fig, ax = plt.subplots(figsize=(12, 6))
>>sns.despine(left=True)
>>sns.distplot(df_user['payment_value'], hist=False)
>>plt.show()
#kmeans 계산을 위한 elbow point 구하기
>>point={}
>>df_revenue = df_user[['payment_value']]
>>for k in range(1, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(df_revenue)
df_revenue["clusters"] = kmeans.labels_
point[k] = kmeans.inertia_
>>plt.figure(figsize=(10, 5))
>>plt.plot(list(point.keys()), list(point.values()))
>>plt.xlabel("Number of cluster")
>>plt.show()
#kmeans
>>kmeans = KMeans(n_clusters=5)
>>kmeans.fit(df_user[['payment_value']])
>>df_user['RevenueCluster'] = kmeans.predict(df_user[['payment_value']])
>>df_user = order_cluster('RevenueCluster', 'payment_value',df_user,True)
>>df_user.groupby('RevenueCluster')['payment_value'].describe()
count mean std min 25% 50% 75% max
RevenueCluster
0 111808.0 227.016754 274.626316 9.59 68.88 128.73 253.79 1812.33
1 2820.0 3396.154103 1622.807945 1814.29 2128.50 2803.17 4118.31 8530.14
2 283.0 13660.994700 3868.599990 8697.99 9859.88 12300.00 17671.00 22346.60
3 99.0 35045.483939 8334.466439 25051.89 27935.46 30186.00 44048.00 45256.00
4 8.0 109312.640000 0.000000 109312.64 109312.64 109312.64 109312.64 109312.64
구매금액의 합계를 구했고 군집 그룹 4로 갈수록 구매금액이 많아지도록 설정하였다.
군집 그룹 0의 구매금액 평균은 227이고 군집 그룹 4의 구매금액 평균 109,312인 것으로 나타났다.
|
점수
|
R(일)
|
F(회)
|
M(금액)
|
|
0
|
446~694
|
0~2
|
0~1812
|
|
1
|
320~445
|
3~6
|
1,813~8,530
|
|
2
|
207~319
|
7~16
|
8,531~22,346
|
|
3
|
100~206
|
17~38
|
22,347~45,256
|
|
4
|
0~99
|
39~75
|
45,256~109,312
|
위의 데이터 분석을 통해 총 5개의 그룹으로 다음과 같은 기준점이 생기는 걸 확인할 수 있다.
이다음 추가적인 작업으로 각각 RFM 수치를 활용하여 등급을 나눌 수 있게 된다.
#RFM 수치를 바탕으로 고객 스코어링 작업
>>df_user.columns = ['customer_unique_id', 'recnecy','recencycluster', 'frequency','frequencycluster','revenue','revenuecluster']
>>df_user['overallscore'] = df_user['recencycluster'] + df_user['frequencycluster'] + df_user['revenuecluster']
#총 스코어링 점수는 11개 나옴
>>df_user.groupby('overallscore')['recnecy','frequency','revenue'].mean()
#점수에 따라 low, mid, high 등급 나누기
>>df_user['segment'] = 'low_value'
>>df_user.loc[df_user['overallscore']>3, 'segment'] = 'mid_value'
>>df_user.loc[df_user['overallscore']>6, 'segment'] = 'high_value'